

Formula di frequenza assoluta, calcolo, distribuzione, esempio
- 3063
- 665
- Benedetta Rinaldi
IL Frecuenza assoluta È definito come il numero di volte in cui gli stessi dati vengono ripetuti nell'insieme delle osservazioni di una variabile numerica. La somma di tutte le frequenze assolute è equivalente a totalizzare i dati.
Quando ci sono molti valori di una variabile statistica, è conveniente organizzarli correttamente per estrarre informazioni sul loro comportamento. Tali informazioni sono fornite dalle misure di tendenza centrale e dalle misure di dispersione.
Figura 1. La frequenza assoluta di un'osservazione statistica è la chiave per trovare la tendenza che segue il set di dati Nei calcoli di queste misure, i dati sono rappresentati attraverso la frequenza con cui appaiono in tutte le osservazioni.
L'esempio seguente mostra quanto sia rivelare la frequenza assoluta di ciascun dati. Durante la prima metà di maggio, queste erano le dimensioni dei migliori costumi da cocktail, di un ben noto magazzino per abbigliamento da donna:
8; 10; 8; 4; 6; 10; 12; 14; 12; 16; 8; 10; 10; 12; 6; 6; 4; 8; 12; 12; 14; 16; 18; 12; 14; 6; 4; 10; 10; 18
Quanti abiti sono venduti in una dimensione particolare, ad esempio taglia 10? I proprietari sono interessati a sapere di fare ordini.
L'ordinazione dei dati è più facile da contare, ci sono esattamente 30 osservazioni in totale, che ordinate dal più piccolo al più alto sono così:
4; 4; 4; 6; 6; 6; 6; 8; 8; 8; 8; 10; 10; 10; 10; 10; 10; 12; 12; 12; 12; 12; 12; 14; 14; 14; 16; 16; 18; 18
E ora è evidente che la dimensione 10 viene ripetuta 6 volte, quindi la sua frequenza assoluta è uguale a 6. La stessa procedura viene eseguita per scoprire la frequenza assoluta delle dimensioni rimanenti.
[TOC]
Formule
La frequenza assoluta, indicata come fYo, È uguale al numero di volte come un certo valore xYo è all'interno del gruppo di osservazioni.
Supponendo che le osservazioni totali siano di n valori, la somma di tutte le frequenze assolute deve essere uguale a detto numero:
Può servirti: papomudas∑fYo = f1 + F2 + F3 +… FN = N
Altre frequenze
Se ogni valore di FYo È diviso per il numero totale di dati n, hai il frequenza relativa FR del valore xYo:
FR = fYo / N
Le frequenze relative sono valori tra 0 e 1, perché n è sempre maggiore di qualsiasi fYo, Ma la somma deve essere uguale a 1.
Moltiplicando per 100 a ciascun valore di FR tu hai il Frequenza percentuale relativa, la cui somma è al 100%:
Frequenza percentuale relativa = (fYo / N) x 100%
È anche importante frequenza accumulata FYo Fino a una certa osservazione, questa è la somma di tutte le frequenze assolute fino a detta di osservazione:
FYo = f1 + F2 + F3 +… FYo
Se la frequenza accumulata è divisa per il numero totale di dati n, si dispone del frequenza relativa accumulata, che si moltiplicano per 100 risultati in percentuale di frequenza relativa accumulata.
Come ottenere la frequenza assoluta?
Per trovare la frequenza assoluta di un certo valore che appartiene a un set di dati, tutti sono organizzati dal minimo al massimo e il valore viene conteggiato.
Nell'esempio delle dimensioni degli abiti, la frequenza assoluta della dimensione 4 è 3 abiti, cioè f1 = 3. Per la taglia 6, sono stati venduti 4 abiti: F2 = 4. Nella taglia 8 4 abiti sono stati venduti anche, f3 = 4 e così via.
Tabulazione
I risultati totali possono essere rappresentati in una tabella che mostra le frequenze assolute di ciascuno:
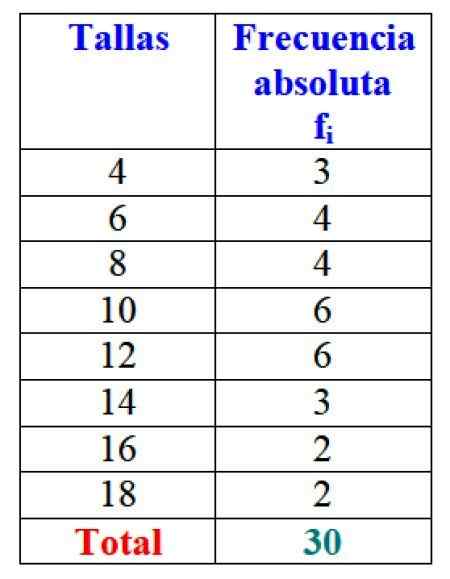 figura 2. Tabella che rappresenta la variabile "venduta venduta" e le rispettive frequenze assolute. Fonte: f. Zapata.
figura 2. Tabella che rappresenta la variabile "venduta venduta" e le rispettive frequenze assolute. Fonte: f. Zapata. Ovviamente è vantaggioso ordinare le informazioni ed essere in grado di accedervi, invece di lavorare con dati sciolti.
Importante: Si noti che aggiungendo tutti i valori della colonna FYo Il numero totale di dati viene sempre ottenuto. In caso contrario, la contabilità deve essere rivista, poiché si verifica un errore.
Tabella di frequenza estesa
La tabella precedente può essere estesa aggiungendo gli altri tipi di frequenza nelle colonne successive a destra:
Può servirti: omocedasticità: ciò che è, importanza ed esempi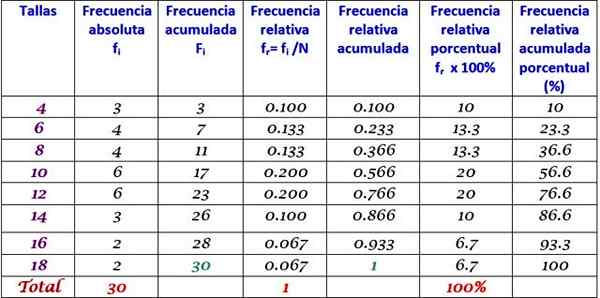
Distribuzione di frequenza
La distribuzione della frequenza è il risultato dell'organizzazione dei dati in termini di frequenze. Quando si lavora con molti dati, è conveniente raggrupparli in categorie, intervalli o classi, ciascuno con le rispettive frequenze: assoluto, relativo, accumulato e percentuale.
L'obiettivo di farlo è accedere più facilmente alle informazioni che i dati contengono, oltre a interpretarli correttamente, il che non è possibile quando vengono presentati senza ordine.
Nell'esempio delle dimensioni, i dati non sono raggruppati, poiché non sono troppe dimensioni e possono essere facilmente manipolati e contati. Le variabili qualitative possono anche essere lavorate in questo modo, ma quando i dati sono molto numerosi, funzionano meglio raggruppandoli nelle classi.
Distribuzione di frequenza per dati raggruppati
Per raggruppare i dati in classi di pari dimensioni, deve essere considerato quanto segue:
-Dimensioni, larghezza o ampiezza di classe: È la differenza tra il valore maggiore della classe e il minore.
La dimensione della classe è decisa dividendo l'intervallo r per il numero di classi da considerare. L'intervallo è la differenza tra il valore massimo dei dati e il minore, come questo:
Dimensione della classe = intervallo / numero di classi.
-Limite di classe: intervallo che passa dal limite inferiore al limite superiore della classe.
-Marchio di classe: È il punto medio dell'intervallo, che è considerato rappresentativo della classe. È calcolato con il semi -limite del limite superiore e il limite inferiore della classe.
-Numero di classi: La formula di Sturges può essere utilizzata:
Classi = 1 + 3.322 log n
Dove n è il numero di classi. Come di solito un numero decimale, quanto segue è arrotondato.
Esempio
Una grande macchina di fabbrica è fuori servizio, poiché ha guasti ricorrenti. I periodi consecutivi di inattività in minuti, di detto macchina, sono registrati di seguito, con un totale di 100 dati:
Può servirti: probabilità di frequenza: concetto, come viene calcolato e esempi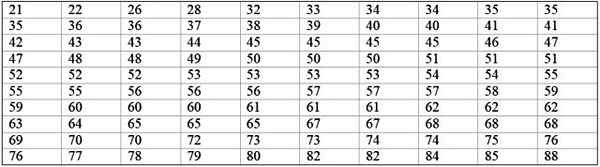
Innanzitutto è determinato il numero di classi:
Classi = 1 + 3,322 log n = 1 + 3.32 log 100 = 7.64 ≈ 8
Dimensione classe = intervallo / numero di classi = (88-21) / 8 = 8.375
È anche un numero decimale, quindi ci vogliono 9 come dimensione della classe.
Il marchio di classe è la media tra il limite superiore e inferiore della classe, ad esempio per la classe [20-29) c'è un segno di:
Marchio di classe = (29 + 20) / 2 = 24.5
Procedere allo stesso modo per trovare i marchi di classe degli intervalli rimanenti.
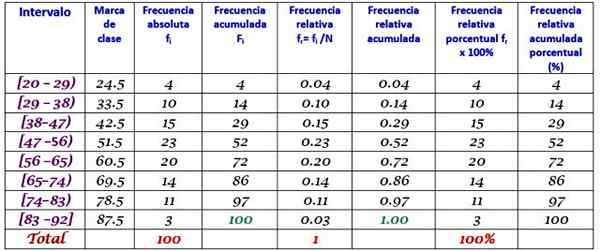
Esercizio risolto
40 giovani hanno indicato che il tempo in pochi minuti trascorsi su Internet domenica scorsa era il prossimo, ordinato sempre più:
0; 12; venti; 35; 35; 38; 40; Quattro cinque; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200; 220.
È richiesto di creare la distribuzione della frequenza di questi dati.
Soluzione
Il rango r dell'insieme di dati n = 40 è:
R = 220 - 0 = 220
L'applicazione della formula di Sturges per determinare il numero di classi produce il seguente risultato:
Classi = 1 + 3,322 log n = 1 + 3.32 log 40 = 6.3
Come è un decimale, l'intero completo è 7, pertanto i dati sono raggruppati in 7 classi. Ogni classe ha una larghezza di:
Dimensione della classe = intervallo / numero di classi = 220/7 = 31.4
Un valore ravvicinato e tondo è 35, quindi viene scelta una larghezza di classe 35.
I segni di classe vengono calcolati in media il limite superiore e inferiore di ciascun intervallo, ad esempio, per l'intervallo [0,35):
Marchio di classe = (0+35)/2 = 17.5
Procediamo allo stesso modo con le classi rimanenti.
Infine, le frequenze vengono calcolate in base alla procedura sopra descritta, risultando nella seguente distribuzione:
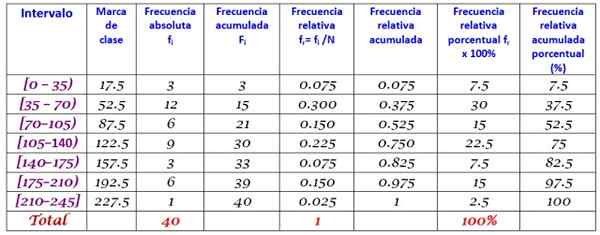
Riferimenti
- Berenson, m. 1985. Statistiche per l'amministrazione ed economia. Inter -American s.A.
- Devore, j. 2012. Probabilità e statistiche per l'ingegneria e la scienza. 8 °. Edizione. Cengage.
- Levin, r. 1988. Statistiche per gli amministratori. 2 °. Edizione. Prentice Hall.
- Spiegel, m. 2009. Statistiche. Serie Schaum. 4 TA. Edizione. McGraw Hill.
- Walpole, r. 2007. Probabilità e statistiche per l'ingegneria e la scienza. Pearson.