

<u>Misure di dispersione principale</u>

- 2888
- 151
- Lidia Valentini
Spieghiamo cosa e quali sono le misure di dispersione e diamo diversi esempi
Quali sono le misure di dispersione?
IL Misure di dispersione o di variazione, nelle statistiche, misura quanto si muove una distribuzione dei dati dal valore di una misura centrale, come la media media o aritmetica. Il suo valore è sempre positivo e normalmente diverso da 0, tranne nel caso di dati identici.
Se una misura di dispersione produce un piccolo valore, significa che i dati si trovano molto vicino alla media, ma se sono grandi, significa che i dati sono più dispersi, quindi, lontano dalla media.
Le misure di dispersione sono molto importanti dal punto di vista statistico, non solo come indicatori aritmetici della variazione dei dati, ma come prezioso aiuto quando si desidera migliorare la qualità, sia nella produzione di prodotti che nella fornitura di servizi.
Esempio di questo sono i ranghi dell'attenzione nelle banche. Il tempo medio di ritardo dei clienti quando effettuano una riga unica e quindi sono distribuiti al botteghino, è lo stesso di se avessero singole linee di fronte a ciascuno.
Tuttavia, la dispersione è inferiore nella riga singola, il che significa che il tempo di attenzione individuale è molto simile a ciascun cliente. I clienti hanno dichiarato di sentirsi più a proprio agio in questo modo, anche se il tempo medio di cura è lo stesso in entrambe le modalità.
Misure di dispersione principale
Quelli principali sono: rango, varianza, deviazione standard e coefficiente di variazione.
Allineare
Il grado R di un set di dati è definito alla differenza tra il valore massimo xMax e il valore minimo xmin del tutto:
Rang = r = valore massimo - valore minimo = xMax - Xmin
Può servirti: quali sono i numeri? Gli 8 usi principaliL'intervallo è rapido da calcolare, ma è molto sensibile ai valori estremi e ha lo svantaggio di non tenere conto dei valori intermedi. Pertanto, viene utilizzato solo per avere un'idea iniziale, abbastanza approssimativa della dispersione dei dati.
Esempio di rango
Questo è un elenco del numero di uragani nell'Atlantico negli ultimi 14 anni:
8; 9; 7; 8; quindici; 9; 6; 5; 8; 4; 12; 7; 8; 2
I dati del valore massimo sono 15 e il valore minimo è 2, quindi:
R = valore massimo - valore minimo = xMax - Xmin = 15 - 2 = 13 uragani
Varianza
Questa misura viene utilizzata per confrontare ciascuno dei dati con la media del set e viene calcolata aggiungendo le differenze, alte quadrate, tra ogni valore con la media e dividendo per il numero totale di valori.
Essere:
-La media: μ
-Qualsiasi valore, appartenente al set di dati: xYo
-Il numero totale di osservazioni: n
Indicando la varianza di una popolazione come σ2, L'espressione per calcolarlo è:
^2&space;N)
E quando viene prelevato un campione di una popolazione, si preferisce calcolare la varianza in questo modo:
^2&space;n)
D'altra parte, l'idea di quadrare ogni differenza tra dati e media è impedire loro di aggiungerli 0, poiché alcune differenze saranno positive e altri negativi, il che tende a annullare la somma. Invece, i quadrati sono sempre positivi.
Può servirti: probabilità di frequenza: concetto, come viene calcolato e esempiQuindi, la varianza è sempre positiva, anche se la differenza tra xYo E la media è negativa e il suo vantaggio principale della varianza è che tiene conto di ogni dati del set.
Ma ha l'inconveniente che le sue unità non siano uguali a quelle dei dati, ad esempio se consiste in tempi, misurati in pochi minuti, la varianza del set verrà fornita in pochi minuti al quadrato.
Esempio di varianza
Il calcolo della varianza richiede di trovare la media. Prendendo i dati sul numero dell'uragano, la media viene calcolata da:

(8 + 9 + 7+ 8 + 15 + 9 + 6 + 5+ 8 + 4 + 12 + 7 + 8+ 2)/14 = 7.7 uragani.Pertanto, la varianza è:
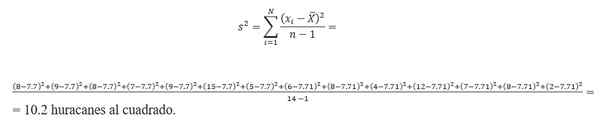
Deviazione standard
Per correggere il problema della mancanza di concordanza tra le unità, la deviazione standard è definita σ, Come la radice quadrata della varianza:
E analogamente, nel caso di un campione:

^2N)
^2n-1)
Esiste una regola empirica per stimare il valore della deviazione standard di un set di dati di esempio, in base all'intervallo. Secondo questa regola, la deviazione standard è di circa un quarto di R:
S ≈ r/4
Ha il vantaggio di consentire una stima rapida della deviazione standard, poiché le operazioni sono molto più semplici.
La deviazione standard è, con molto, la misura di dispersione più comunemente usata, quindi vale la pena evidenziare le sue caratteristiche principali:
- La deviazione standard indica quanto si allontanano i dati dei media
- È sempre positivo, ma può essere 0 se tutti i dati sono identici
- Maggiore è il valore della deviazione standard, più si dispettono i dati
- Le unità di deviazione standard sono le stesse di quelle della variabile in studio
- Il suo valore cambia rapidamente quando uno dei dati (o più) ha un valore molto diverso dal resto
- I valori di deviazione standard sono distorti, cioè le medie della deviazione standard non sono distribuite attorno alla media, in contrasto con la varianza, che non è bisia.
Esempio di deviazione standard
Continuando con l'esempio degli uragani, la deviazione standard è:

Oppure, se si preferisce utilizzare l'approccio della deviazione standard attraverso l'intervallo, si ottiene un valore abbastanza vicino:
S = 13/4 = 3.25
Coefficiente di variazione
Il coefficiente di variazione è indicato dalle iniziali CV o R, in alcuni testi, e sia per una popolazione, e per un campione, mette in relazione la deviazione standard e media, in percentuale:
\times&space;100)
O Bene:
\times&space;100)
Le equazioni sono valide fintanto che la media è diversa da 0.
Di norma, il coefficiente di variazione è arrotondato a un singolo decimale e viene utilizzato per confrontare i dati di due popolazioni diverse.
Esempio di coefficiente di variazione
I tempi di attesa in pochi secondi, per i clienti di una banca, sono registrati in due situazioni: quando fanno una riga unica e quando fanno i ranghi individuali prima della biglietteria di attenzione. I risultati sono i seguenti:

Entrambi i set di dati possono essere confrontati attraverso il rispettivo coefficiente di variazione:
Fila unica
- Media = 429 secondi
- Deviazione = 28.6 secondi
- Cv = (28.6/429) x 100 = 6.7 %
Classi individuali
- Media = 429 secondi
- Deviazione = 109.3 secondi
- Cv = (109.3/429) x 100 = 25.5 %
Poiché quest'ultimo valore è maggiore, ciò indica che esiste una maggiore variabilità nei tempi di servizio clienti quando producono singoli ranghi rispetto a quando fanno una riga unica, sebbene il tempo medio sia lo stesso in ogni caso.