

Stima per intervalli
- 1137
- 119
- Silvano Montanari
Qual è la stima per intervalli?
IL Stima per intervalli È il modo per determinare l'intervallo di valori in cui può essere inclusa la media della popolazione, in base alle informazioni di un campione di dimensioni finite, estratto casualmente dalla popolazione totale.
Lui Intervallo di stima È più basso poiché il campione è più grande, ma diventa più ampio se il livello o la percentuale di affidabilità degli stessi aumenti.
Se desideri conoscere la media della popolazione di una determinata variabile in forma esatta, allora la popolazione totale dovrebbe essere considerata, qualcosa che non è sempre fattibile, poiché se è una popolazione molto grande, è costoso ottenere i dati del l'intera popolazione. Per questo motivo, vengono utilizzati uno o più campioni casuali della popolazione totale.
Si basa sull'ipotesi che, estraendo un campione casuale, non distorto e prendendo in considerazione proporzionalmente tutti gli strati, quindi il valore medio del campione deve essere molto vicino a quello della media della popolazione.
La logica indica che maggiore è i dati del campione, la differenza tra il valore del campione medio e il valore medio della popolazione è inferiore.
Intervallo di stima
In pratica, a meno che la popolazione completa non sia nota, è possibile solo trovare, con una certa probabilità, l'intervallo in cui si può trovare la media della popolazione, basato su un campione di dimensioni finite.
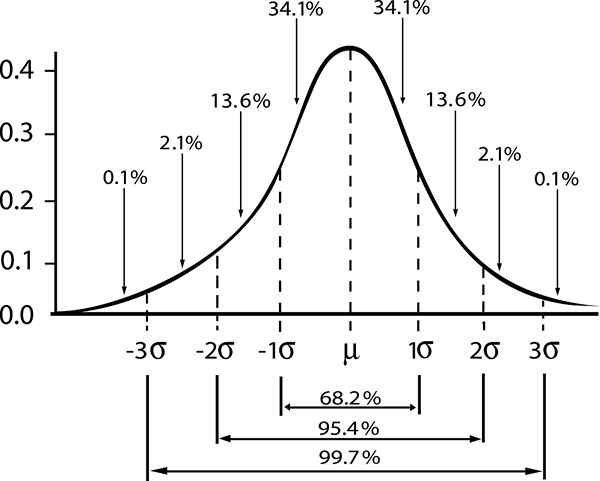
Nel caso di una popolazione che segue una distribuzione normale, con Deviazione standard σ , IL Differenza standard Tra la media della popolazione μ e il campione medio di dimensioni N è dato da:
| μ - | ≤ σ / √n
Qui, la parola "standard" indica che il 68% dei campioni di dimensioni N, Hanno un valore medio tra l'intervallo [μ - σ / √n, μ + σ / √n].
Può servirti: criteri di divisibilità: cosa sono, quali sono l'uso e le regoleStima standard
Un'interpretazione alternativa di quanto sopra significa dire che la popolazione media ottenuta da un campione di dimensioni N e il valore medio è compreso nell'intervallo [ - σ / √n, + σ / √n], Con probabilità del 68%.
Nella maggior parte dei casi reali, non è possibile conoscere la deviazione della popolazione standard, quindi σ È approssimato dalla deviazione standard del campione S, che viene calcolato come segue:
S = √ (∑ (xYo - )2 / √ (N-1).
Da lì si ottiene l'intervallo che potrebbe contenere la media della popolazione con un livello di confidenza del 68% (livello di confidenza standard), dato da:
-S / √n ≤ μ ≤ + s / √n
Questo intervallo di misurazione della popolazione è noto come Intervallo di stima standard e è stato ottenuto solo con i dati disponibili in dimensioni N.
Dalla formula precedente segue che, se si desidera rafforzare l'intervallo di stima a metà, è necessario quadruplicare La dimensione del campione.
Stima per intervalli di confidenza
In alcuni studi, un livello standard del 68% può essere insufficiente, quindi è necessario determinare gli intervalli con un livello di confidenza arbitraria γ.
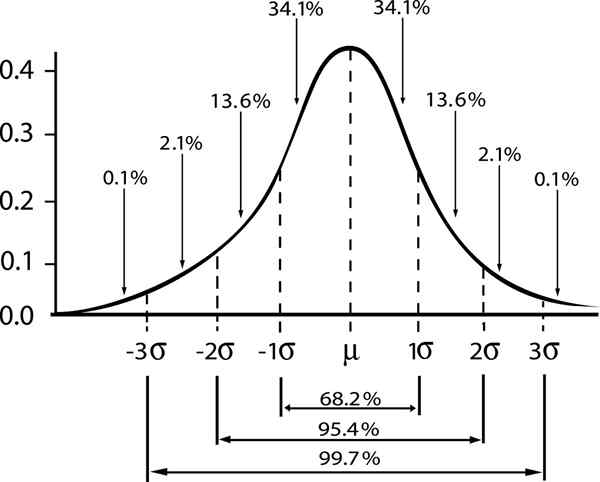 Viene mostrata la relazione tra il margine di affidabilità e l'intervallo in una distribuzione gaussiana
Viene mostrata la relazione tra il margine di affidabilità e l'intervallo in una distribuzione gaussiana Se denotiamo da ε L'errore standard S/√n, quindi l'errore di stima per un livello di confidenza γ sarà dato da:
E = Zγ⋅ε.
Dove Zγ È un numero con cui si moltiplica l'errore standard e quindi ottenere il margine di errore con un livello di confidenza arbitraria γ.
Per ottenere il fattore Zγ, procedi come segue:
Può servirti: numeri razionali: proprietà, esempi e operazioniPasso 1
È la chiamata Livello di significato α corrispondente al livello di fiducia γ dalla seguente formula:
α = 1 - γ
Passo 2
Il valore è determinato:

Passaggio 3
Si schiarisce Zγ L'equazione:
N (Zγ) = 1 - α/2
Poiché è un'equazione integrale, questo gioco è ottenuto dalle normali tabelle di distribuzione, usando il metodo di interpolazione lineare.
Passaggio 4
In alternativa all'uso delle tabelle, le funzioni statistiche incorporate nei fogli di calcolo come Eccellere, O Foglio di Google. Questi programmi incorporano la normale funzione inversa N-1, in modo che il fattore di correzione Zγ Si ottiene direttamente valutando questa funzione inversa:
Zγ = n-1(1 - α/2).
Intervalli di fiducia tipici
I livelli di confidenza più frequentemente usati sono:
- Zγ = 1; Livello di confidenza standard γ = 0,68.
- Zγ = 2; livello di confidenza γ = 0,95 (o livello di significatività 5%).
- Zγ = 3; livello di confidenza γ = 0,997 (o 0,3%di livello di significatività)
Esempi
Esempio 1
Determina l'intervallo medio di peso dei neonati durante il mese di agosto in una grande città basata su un campione casuale di 100 bambini, in cui è stato ottenuto un peso medio di 3100 grammi con una deviazione standard del campione S = 1500 grammi.
Soluzione
Innanzitutto, viene determinato l'errore standard del campione:
ε = s/√n = (1500 g)/√100 = 150 g.
Pertanto, a partire da questo campione, si può dedurre che il peso medio dei bambini nati ad agosto in quella città è compreso tra 2950 g e 3250 g, con probabilità del 68%.
Esempio 2
Supponiamo che le dimensioni del campione di bambini nati nello stesso mese di agosto e nella stessa città dell'esempio 1. Il peso medio del campione è di 3100 g con una dispersione standard di 1500 g.
Può servirti: decomposizione di numeri naturali (esempi ed esercizi)È richiesto di stimare l'intervallo di peso medio dei neonati di quella città, da questo nuovo campione.
Soluzione
Ora l'errore standard diminuisce nel fattore 1/√2, Quindi il nuovo errore standard del peso medio sarà di 106 g.
Quindi si può stimare, da questo nuovo campione che il peso medio dei neonati è compreso nell'intervallo da 2994 g a 3206 g, con una probabilità del 68%.
Esercizi
Esercizio 1
Determinare l'intervallo di peso medio di neonati in agosto, a partire dal campione specificato nell'esempio 1, con una probabilità del 95%.
Soluzione
Un livello di affidabilità del 95% raddoppia l'intervallo di peso medio, rispetto a un livello di affidabilità del 68%.
Pertanto, il peso medio dei neonati è incluso nell'intervallo di 2800 grammi a 3400 grammi con certezza al 95%.
Esercizio 2
Stimare con un livello di confidenza del 99,7% l'intervallo in cui si trova il peso medio dei neonati da una grande città, se è disponibile un campione con il peso medio di 100 bambini pari a 3100 g e con una deviazione del campione standard S = 1500 G.
Soluzione
Il margine di errore di peso medio, con il 99,7% di certezza, sarà triplicato l'errore medio, cioè:
3*1500/√100.
Quindi si deduce, da questo campione, che il peso medio dei neonati sarà incluso nell'intervallo: 2650 grammi a 3550 grammi, con un livello di certezza del 99,7%.
Da questo risultato si osserva come con un livello maggiore di certezza aumenta l'incertezza del peso medio a un intervallo molto più ampio.