

I dati non raggruppavano esempi ed esercizio fisico risolti

- 3918
- 313
- Dante Morelli
IL Dati non group Sono quelli che, ottenuti da uno studio, non sono ancora organizzati per lezioni. Quando si tratta di un numero gestibile di dati, di solito 20 o meno, e ci sono pochi dati diversi, possono essere trattati come non raggruppati ed estrarre informazioni preziose da loro.
I dati non gruppi provengono dall'indagine o dallo studio condotto per ottenerli e quindi mancano di elaborazione. Diamo un'occhiata ad alcuni esempi:
Figura 1. I dati non gruppi provengono direttamente da qualsiasi studio e non sono stati classificati. Fonte: pxhere. -Risultati di un esame CI del coefficiente intellettuale presso 20 studenti casuali di un'università. I dati ottenuti erano i seguenti:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112.106
-Età di 20 dipendenti di una mensa molto popolare:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 19, 22, 27, 29, 23, 20
-Le note finali medie di 10 studenti di una lezione di matematica:
3.2; 3.1; 2,4; 4.0; 3.5; 3.0; 3.5; 3.8; 4.2; 4.9
[TOC]
Proprietà dei dati
Esistono tre importanti proprietà che caratterizzano una serie di dati statistici sono raggruppati o meno, che sono:
-Posizione, che è la tendenza dei dati ad essere raggruppati attorno a determinati valori.
-Dispersione, Un indicativo di come dispersi o divulgati sono i dati attorno a un certo valore.
-Forma, Si riferisce al modo in cui sono distribuiti i dati, che può essere visto quando viene costruito un grafico. Ci sono curve molto simmetriche e anche distorte, a sinistra o a destra di un certo valore centrale.
Per ciascuna di queste proprietà ci sono una serie di misure che le descrivono. Una volta ottenuti, ci danno un panorama del comportamento dei dati:
-Le misure di posizione più utilizzate sono la media aritmetica o semplicemente media, mediana e moda.
-Nella dispersione vengono frequentemente utilizzati l'intervallo, la varianza e la deviazione standard, ma non sono le uniche misure di dispersione.
Può servirti: omotecia-E per determinare la forma, la media e la mediana vengono confrontate tramite bias, come si vedrà a breve.
Calcolo di media, mediana e moda
-La media aritmetica, Conosciuto anche come media e indicato come X, viene calcolato come segue:
X = (x1 + X2 + X3 +... XN) / N
Dove x1, X2,.. . XN, sono i dati e n è il totale di essi. In sintesi di somma c'è:

-La mediana È il valore che appare nel mezzo di una successione ordinata di dati, pertanto per ottenerli, è necessario ordinare prima i dati.
Se il numero di osservazioni è dispari, non vi è alcun problema nel trovare il punto medio del set, ma se abbiamo una coppia di dati, i due dati centrali vengono ricercati e mediati.
-Moda È il valore più comune osservato nel set di dati. Non esiste sempre, poiché è possibile che nessun valore venga ripetuto più frequentemente di un altro. Potrebbero esserci anche due dati con uguale frequenza, nel qual caso si parla di una distribuzione bi-modale.
A differenza delle due misure precedenti, la moda può essere utilizzata con dati qualitativi.
Vediamo come vengono calcolate queste misure di posizione con un esempio:
Esempio risolto
Supponiamo di voler determinare la media aritmetica, la mediana e la moda nell'esempio proposto all'inizio: i 20 dipendenti di una mensa:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 19, 22, 27, 29, 23, 20
IL metà Viene calcolato semplicemente aggiungendo tutti i valori e dividendo per n = 20, che è il numero totale di dati. Da questa parte:
Può servirti: relazioni di proporzionalità: concetto, esempi ed eserciziX = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22.3 anni.
Per trovare il mediano È necessario ordinare prima il set di dati:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Come sono un paio di dati, i due dati centrali, evidenziati in grassetto, vengono presi e mediati. Perché entrambi hanno 22 anni, la mediana è di 22 anni.
Finalmente il moda È il fatto che si ripete maggiormente o che la cui frequenza è maggiore, essendo questi 22 anni.
Intervallo, varianza, deviazione standard e distorsioni
L'intervallo è semplicemente la differenza tra il maggiore e l'ultimo dei dati e consente alla loro variabilità di apprezzare rapidamente. Ma a parte, ci sono altre misure di dispersione che offrono maggiori informazioni sulla distribuzione dei dati.
Varianza e deviazione standard
La varianza è indicata come S e viene calcolata per espressione:
^2n)
^2n-1)
Quindi interpretare giustamente i risultati, è definita la deviazione standard come la radice quadrata della varianza, o anche la quasi-deviazione standard, che è la radice quadrata della quasivarianza:
^2n)
^2n-1) Pregiudizio
Pregiudizio
È il confronto tra la media media e la mediana:
-Sì Med = Media x: i dati sono simmetrici.
-Quando x> med: distorto a destra.
-E se x < Med: los datos sesgan hacia la izquierda.
Esercizio risolto
Trova media, mediana, moda, rango, varianza, deviazione standard e pregiudizio per i risultati di un esame del coefficiente intellettuale di 20 studenti di un'università:
Può servirti: funzioni matematiche119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Soluzione
Ordineremo i dati, poiché sarà necessario trovare la mediana.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
E li metteremo in un tavolo come segue, per facilitare i calcoli. La seconda colonna intitolata "accumulata" è la somma dei dati corrispondenti più i precedenti.
Questa colonna troverà facilmente la media, dividendo l'ultimo accumulato tra il numero totale di dati, come si vede alla fine della colonna "accumulata":
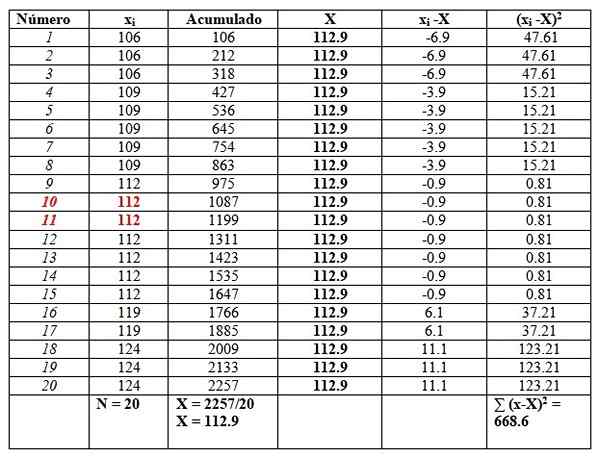
X = 112.9
La mediana è la media dei dati centrali evidenziati in rosso: numero 10 e numero 11. Come lo stesso, la mediana è 112.
Infine, la moda è il valore più ripetuto ed è 112, con 7 ripetizioni.
Per quanto riguarda le misure di dispersione, l'intervallo è:
124-106 = 18.
La varianza si ottiene dividendo il risultato finale della colonna destra tra N:
S = 668.6/20 = 33.42
In questo caso, la deviazione standard è la radice quadrata della varianza: √33.42 = 5.8.
D'altra parte, i valori della quasivarialità e della deviazione standard quasi sono:
SC= 668.6/19 = 35.2
Quasi-deviazione standard = √35.2 = 5.9
Infine, la distorsione è leggermente a destra, poiché la media 112.9 è maggiore della mediana 112.
Riferimenti
- Berenson, m. 1985. Statistiche per l'amministrazione ed economia. Inter -American s.A.
- Canavos, g. 1988. Probabilità e statistiche: applicazioni e metodi. McGraw Hill.
- Devore, j. 2012. Probabilità e statistiche per l'ingegneria e la scienza. 8 °. Edizione. Cengage.
- Levin, r. 1988. Statistiche per gli amministratori. 2 °. Edizione. Prentice Hall.
- Walpole, r. 2007. Probabilità e statistiche per l'ingegneria e la scienza. Pearson.
- « Gradi di libertà come calcolarli, tipi, esempi
- Tipi di assiomi di probabilità, spiegazione, esempi, esercizi »