

Elementi del modello di database relazionale, come farlo, esempio
- 3925
- 355
- Zelida Gatti
Lui Modello relazionale di database È un metodo per strutturare i dati usando le relazioni, attraverso strutture a forma di griglia, che consistono in colonne e righe. È il principio concettuale dei database relazionali. È stato proposto da Edgar F. CODD nel 1969.
Da allora è diventato il modello di database dominante per applicazioni commerciali, se confrontato con altri modelli di database, come gerarchici, rete e oggetti.
Fonte: Pixabay.com CODD non aveva idea del estremamente vitale e influente che sarebbe stato il suo lavoro come piattaforma per i database relazionali. La maggior parte delle persone ha molta familiarità con l'espressione fisica di una relazione in un database: la tabella.
Il modello relazionale è definito come il database che consente di raggruppare i propri elementi di dati in una o più tabelle indipendenti, che possono essere correlate tra loro utilizzando campi comuni a ciascuna tabella correlata.
[TOC]
Gestione del database
Un database è simile a un foglio di calcolo. Tuttavia, le relazioni che possono essere create tra le tabelle consentono a un database relazionale di archiviare in modo efficiente una grande quantità di dati, che possono essere recuperati in modo efficace.
Lo scopo del modello relazionale è di fornire un metodo dichiarativo per specificare i dati e le consultazioni: gli utenti dichiarano direttamente quali informazioni contiene il database e quali informazioni desideri da esso.
D'altra parte, consentono al software del sistema di gestione del database responsabile della descrizione delle strutture di dati per la procedura di archiviazione e recupero per rispondere.
La maggior parte dei database relazionali utilizza la lingua SQL per la consultazione e la definizione dei dati. Esistono attualmente molti sistemi di gestione dei database relazionali o RDBM (sistema di gestione della base di dati relazionali), come Oracle, IBM DB2 e Microsoft SQL Server.
Caratteristiche ed elementi
- Tutti i dati sono concettualmente rappresentati come una disposizione ordinata di dati in righe e colonne, chiamata relazione o tabella.
- Ogni tavolo deve avere un'intestazione e un corpo. L'intestazione è semplicemente l'elenco delle colonne. Il corpo è l'insieme di dati che riempie la tabella, organizzati in righe.
- Tutti i valori sono salite. Cioè, in una data posizione di riga/colonna nella tabella, c'è solo un valore univoco.
-Elementi
La figura seguente mostra una tabella con i nomi dei suoi elementi di base, che costituiscono una struttura completa.
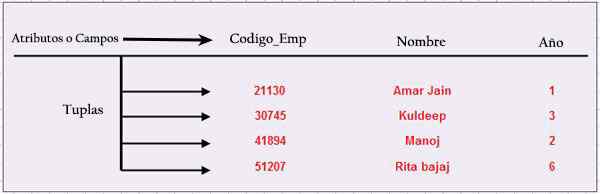
Tupla
Ogni riga di dati è una tupla, nota anche come registrazione. Ogni riga è un n-tupla, ma il "n-" è generalmente escluso.
Colonna
Ogni colonna di una tupla è chiamata attributo o campo. La colonna rappresenta l'insieme di valori che può avere un attributo specifico.
Traccia
Ogni riga ha una o più colonne chiamate tabella. Questo valore combinato è unico per tutte le righe di una tabella. Attraverso questa chiave, ogni tupla verrà identificata in modo univoco. Cioè, la chiave non può essere duplicata. Si chiama chiave primaria.
D'altra parte, una chiave esterna o secondaria è il campo di una tabella che si riferisce alla chiave primaria di qualche altra tabella. È usato per fare riferimento alla tabella primaria.
-Regole di integrità
Quando si progettano il modello relazionale, sono definite alcune condizioni che devono essere soddisfatte nel database, chiamate regole di integrità.
Può servirti: macrocomputer: storia, caratteristiche, usi, esempiIntegrità chiave
La chiave primaria deve essere unica per tutte le tuple e non può avere il valore null (null). Altrimenti, non sarai in grado di identificare la riga esclusivamente.
Per una chiave composta da diverse colonne, nessuna di queste colonne può contenere null.
Integrità referenziale
Ogni valore di una chiave esterna deve coincidere con un valore della chiave primaria nella tabella referenziata o primaria.
Nella tabella secondaria è possibile inserire solo una riga con una chiave esterna se quel valore esiste in una tabella primaria.
Se il valore delle modifiche chiave nella tabella primaria, per l'aggiornamento o l'eliminazione della riga, tutte le righe nelle tabelle secondarie con questa chiave esterna devono essere aggiornate o eliminate di conseguenza.
Come creare un modello relazionale?
-Raccogliere dati
I dati necessari per archiviarli nel database devono essere raccolti. Questi dati sono divisi in diverse tabelle.
È necessario scegliere un tipo di dati appropriato per ogni colonna. Ad esempio: numeri interi, numeri di punti mobili, testo, data, ecc.
-Definire le chiavi primarie
Per ogni tabella è necessario scegliere una colonna (o poche colonne) come chiave primaria, che identificherà in modo univoco ogni riga della tabella. La chiave primaria viene anche utilizzata per fare riferimento ad altre tabelle.
-Crea relazioni tra le tabelle
Un database composto da tabelle indipendenti e non correlate ha poco scopo.
L'aspetto più cruciale nella progettazione di un database relazionale è identificare le relazioni tra le tabelle. I tipi di relazione sono:
Uno a molti
In un database di "classi", un insegnante può insegnare a zero o più lezioni, mentre una lezione viene insegnata da un singolo insegnante. Questo tipo di relazione è noto come uno a molti.
Questa relazione non può essere rappresentata in una singola tabella. Nel database "elenco di classe" puoi avere una tabella chiamata insegnanti, che memorizza informazioni sugli insegnanti.
Per archiviare le lezioni tenute da ogni insegnante, potrebbero essere create colonne aggiuntive, ma un problema dovrebbe affrontare: quante colonne creano.
D'altra parte, se hai una tabella chiamata Classes, memorizza informazioni su una classe, potrebbero essere create colonne aggiuntive per archiviare informazioni sull'insegnante.
Tuttavia, come insegnante può insegnare in molte classi, i suoi dati sarebbero raddoppiati in molti ranghi nelle classi tabella.
Progetta due tavoli
Pertanto, è necessario progettare due tabelle: una tabella delle classi per archiviare informazioni sulle classi, con la classe principale come chiave principale e una tabella principale per archiviare informazioni sugli insegnanti, con Teacher_id come chiave principale.
Quindi è possibile creare la relazione uno per molti conservire la chiave primaria della tabella master (Master_id) nella tabella delle classi, come illustrato di seguito.
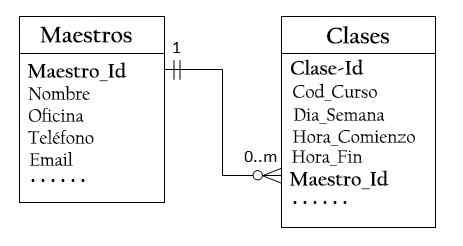
La colonna Master_id nella tabella delle classi è nota come chiave esterna o secondaria.
Per ogni valore Master_id nella tabella principale, potrebbero esserci zero o più righe nella tabella delle classi. Per ogni valore Class_id nella tabella delle classi, c'è solo una riga nella tabella principale.
Molti a molti
In un database di "vendita di prodotti", l'ordine di un cliente può contenere diversi prodotti e un prodotto può apparire in diversi ordini. Questo tipo di relazione è noto come molti a molti.
Può servirti: ICT (tecnologie di informazione e comunicazione)È possibile avviare il database di "vendita di prodotti" con due tabelle: prodotti e ordini. La tabella dei prodotti contiene informazioni sui prodotti, con il prodotto come chiave primaria.
D'altra parte, gli ordini contengono ordini dei clienti, con la richiesta come codice primario.
Non è possibile archiviare i prodotti richiesti all'interno della tabella ordinata, poiché non è noto quante colonne riservano per i prodotti. Né gli ordini possono essere conservati nei prodotti da tavola per lo stesso motivo.
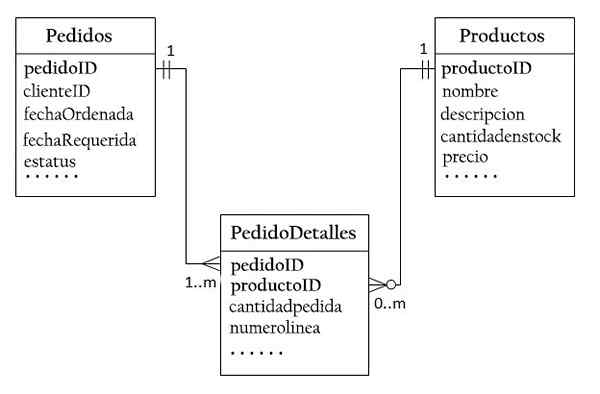
Per ammettere una relazione con molti con molti, è necessario creare una terza tabella, nota come tabella sindacale (che richiede), in cui ogni riga rappresenta un elemento di un ordine particolare.
Per la tabella richiedente, la chiave primaria è composta da due colonne: ordine e prodotto, identificando ogni riga ogni riga.
Le colonne richieste e del prodotto nella richiesta di metodi vengono utilizzate per fare riferimento agli ordini e ai prodotti. Pertanto, sono anche chiavi esterne alla richiesta per la richiesta.
Uno per uno
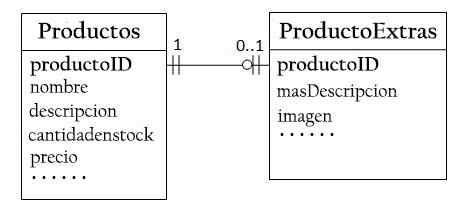
Nel database "Products Sale", un prodotto può avere informazioni opzionali, come una descrizione aggiuntiva e la sua immagine. Tienilo all'interno dei prodotti genererebbe molti spazi vuoti.
Pertanto, è possibile creare un'altra tabella (prodotto Extexts) per archiviare i dati opzionali. Verrà creato solo un record per prodotti con dati opzionali.
I due tavoli, prodotti e prodotti, hanno una relazione da una a. Per ogni riga nella tabella del prodotto c'è una riga massima nei prodotti Tablexts. Lo stesso prodotto dovrebbe essere utilizzato come la chiave principale per entrambe le tabelle.
Vantaggi
Indipendenza strutturale
Nel modello di database relazionale, le modifiche nella struttura del database non influiscono sull'accesso ai dati.
Quando è possibile apportare modifiche alla struttura del database senza influire sulla capacità del DBMS di accedere ai dati, si può dire che è stata raggiunta l'indipendenza strutturale.
Semplicità concettuale
Il modello di database relazionale è ancora più semplice a livello concettuale rispetto al modello gerarchico o alla rete di database.
Poiché il modello di database relazionale rilascia il progettista dai dettagli dell'archiviazione fisica dei dati, i progettisti possono concentrarsi sulla vista logica del database.
Facilità di progettazione, implementazione, manutenzione e utilizzo
Il modello di database relazionale raggiunge sia l'indipendenza dei dati sia l'indipendenza della struttura, il che rende molto più semplice la progettazione, la manutenzione, l'amministrazione e l'uso del database.
Capacità di consultazione ad hoc
La presenza di una capacità di consultazione molto potente, flessibile e facile da usare è una delle ragioni principali dell'immensa popolarità del modello di base relazionale del database.
Il linguaggio di consultazione del modello di database relazionale, chiamato linguaggio di consultazione strutturato o SQL, realizza le query ad hoc. SQL è una lingua di quarta generazione (4GL).
Un 4GL consente all'utente di specificare cosa dovrebbe essere fatto, senza specificare come dovrebbe essere fatto. Pertanto, con gli utenti SQL possono specificare quali informazioni desiderano e lasciare i dettagli su come ottenere le informazioni nel database.
Svantaggi
Spese hardware
Il modello di database relazionale nasconde le complessità della sua implementazione e i dettagli dell'archiviazione fisica dei dati dell'utente.
Può servirti: quali sono i codici G? (Con esempio)Per fare ciò, i sistemi di database relazionali necessitano di computer con hardware e archiviazione più potenti.
Pertanto, RDBMS ha bisogno di macchine potenti per funzionare senza problemi. Tuttavia, poiché la potenza di elaborazione dei computer moderni sta aumentando a un ritmo esponenziale, la necessità di una maggiore potenza di elaborazione nello scenario attuale non è più un problema molto grande.
La facilità di progettazione può portare a un cattivo design
Il database relazionale è facile da progettare e utilizzare. Gli utenti non hanno bisogno di conoscere i dettagli complessi dell'archiviazione fisica dei dati. Non hanno bisogno di sapere come i dati vengono davvero archiviati per accedervi.
Questa facilità di progettazione e utilizzo può portare allo sviluppo e all'implementazione di sistemi di gestione del database molto scarsamente progettati. Poiché il database è efficiente, queste inefficienze del design non verranno alla luce quando il database è progettato e quando c'è solo una piccola quantità di dati.
Man mano che il database cresce, i database mal progettati rallenteranno il sistema e causano una degradazione delle prestazioni dei dati e della corruzione.
Fenomeno delle "Isole di informazione"
Come detto prima, i sistemi di database relazionale sono facili da implementare e utilizzare. Ciò creerà una situazione in cui troppe persone o dipartimenti creeranno i propri database e applicazioni.
Queste isole di informazione eviteranno l'integrazione delle informazioni, che è essenziale per il funzionamento fluido ed efficiente dell'organizzazione.
Questi singoli database creeranno anche problemi come incoerenza dei dati, duplicazione dei dati, ridondanza dei dati, ecc.
Esempio
Supponiamo che un database composto da tabelle di supposizione, pezzi e spedizioni. La struttura delle tabelle e alcuni record di esempio sono presentati di seguito:
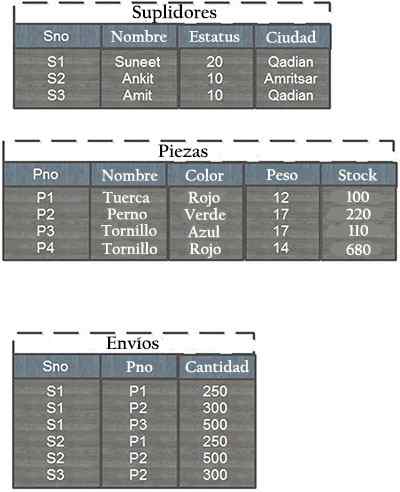
Ogni riga nella tabella di fornitura è identificata da un numero di fornitori univoco (SNO), identificando in modo univoco ogni riga della tabella. Allo stesso modo, ogni pezzo ha un numero di parte unico (PNO).
Inoltre, non ci può essere più di una spedizione per una determinata combinazione fornitore / pezzo nella tabella di spedizione, poiché questa combinazione è la chiave di spedizione primaria, che funge da tavolo sindacale, poiché molti sono una relazione con molti con molti.
La relazione tra le tabelle e le spedizioni è data dall'avere in comune il campo PNO (numero di pezzo) e la relazione tra fornitori e spedizioni deriva dall'avere in comune il campo SNO (numero del fornitore).
L'analisi della tabella delle spedizioni può essere ottenuta come informazioni che vengono inviate un totale di 500 dadi dai fornitori di Suneet e Ankit, 250 ciascuno.
Allo stesso modo, 1 sono stati inviati.100 bulloni in totale da tre diversi fornitori. 500 viti blu sono state inviate dal fornitore Suneet. Non ci sono spedizioni a vite rosse.
Riferimenti
- Wikipedia, The Free Encyclopedia (2019). Modello relazionale. Preso da: in.Wikipedia.org.
- Ravepedia (2019). Modello relazionale. Preso da: Ravepedia.com.
- Diesh Thakur (2019). Modello relazionale. Note di ecomputer. Tratto da: ecomputernotes.com.
- Geeks for Geeks (2019). Modello relazionale. Tratto da: geeksforgeeks.org.
- Nanyang Technological University (2019). Un tutorial a carrello rapido sulla progettazione del database relazionale. Preso da: NTU.Edu.Sg.
- Adrienne Watt (2019). Capitolo 7 Il modello di dati relazionali. BC Open Textbooks. Tratto da: OpenTextBC.AC.
- Toppr (2019). Database e schemi relazionali. Preso da: toppr.com.
- « Ricerca operazioni a cosa serve, modelli, applicazioni
- Storia, proprietà, struttura, struttura del vanadio »