

Metodologia di campionamento casuale, vantaggi, svantaggi, esempi

- 2825
- 516
- Enzo De Angelis
Lui campionamento Casuale È il modo di selezionare un campione statisticamente rappresentativo da una determinata popolazione. Parte del principio secondo cui ogni elemento del campione deve avere la stessa probabilità di essere selezionato.
Una lotteria è un esempio di campionamento casuale, in cui a ciascun membro della popolazione di partecipanti viene assegnato un numero. Per scegliere i numeri corrispondenti ai premi della lotteria (il campione) viene utilizzata alcune tecniche casuali, ad esempio estratto da una cassetta postale i numeri che sono stati valutati su schede identiche.
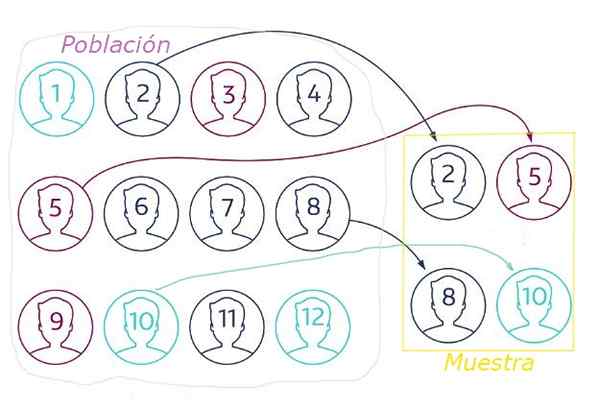 Figura 1. Nel campionamento casuale il campione viene estratto dalla popolazione casuale attraverso una tecnica che garantisce che tutti gli elementi abbiano la stessa probabilità di essere scelti. Fonte: netquest.com.
Figura 1. Nel campionamento casuale il campione viene estratto dalla popolazione casuale attraverso una tecnica che garantisce che tutti gli elementi abbiano la stessa probabilità di essere scelti. Fonte: netquest.com. Nel campionamento casuale è essenziale.
[TOC]
La dimensione del campione
Esistono formule per determinare la dimensione adeguata di un campione. Il fattore più importante da considerare è se la dimensione della popolazione è nota o meno. Diamo un'occhiata alle formule per determinare la dimensione del campione:
Caso 1: la dimensione della popolazione non è nota
Quando la dimensione della popolazione è sconosciuta, è possibile selezionare un campione N adeguato, per determinare se una determinata ipotesi è vera o falsa.
Per questo, viene utilizzata la seguente formula:
n = (z2 P Q)/(E2)
Dove:
-P è la probabilità che l'ipotesi sia vera.
-Q è la probabilità che non lo sia, quindi Q = 1 - P.
-E è il margine di errore relativo, ad esempio un errore del 5% ha un margine E = 0,05.
-Z ha a che fare con il livello di fiducia richiesto dallo studio.
Può servirti: distribuzione normale: formula, caratteristiche, esempio, esercizio fisicoIn una distribuzione normale caratterizzata (o normalizzata), un livello di confidenza al 90% ha z = 1.645, poiché la probabilità che il risultato sia compreso tra -1.645σ e +1.645σ è del 90%, dove σ è la deviazione standard.
Livelli di fiducia e loro corrispondenti valori z
1.- Il livello di confidenza al 50% corrisponde a z = 0,675.
2.- 68.Il livello di confidenza al 3% corrisponde a z = 1.
3.- Livello di confidenza al 90% equivalente a z = 1.645.
4.- Il livello di confidenza al 95% corrisponde a z = 1,96
5.- Il livello di confidenza al 95,5% corrisponde a z = 2.
6.- Il livello di confidenza al 99,7% è equivalente a z = 3.
Un esempio in cui questa formula può essere applicata sarebbe in uno studio per determinare il peso medio dei ciottoli di una spiaggia.
Chiaramente non è possibile studiare e pesare tutti i ciottoli della spiaggia, quindi è conveniente.
 figura 2. Per studiare le caratteristiche dei ciottoli di una spiaggia è necessario scegliere un campione casuale con un numero rappresentativo di essi. (Fonte: Pixabay)
figura 2. Per studiare le caratteristiche dei ciottoli di una spiaggia è necessario scegliere un campione casuale con un numero rappresentativo di essi. (Fonte: Pixabay) Caso 2: la dimensione della popolazione è nota
Quando è noto il numero N di elementi che compongono una determinata popolazione (o universo), se si desidera selezionare un semplice campionamento casuale un campione statisticamente significativo, questa è la formula:
n = (z2p Q n)/(n e2 + Z2P Q)
Dove:
-Z è il coefficiente associato al livello di fiducia.
-P è la probabilità di successo dell'ipotesi.
-Q è la probabilità di fallimento nell'ipotesi, p + q = 1.
-N è la dimensione della popolazione totale.
-E è l'errore relativo del risultato dello studio.
Esempi
La metodologia per estrarre i campioni dipende molto dal tipo di studio necessario per fare. Pertanto, il campionamento casuale ha innumerevoli applicazioni:
Può servirti: segni di raggruppamentoSondaggi e questionari
Ad esempio nei sondaggi telefonici, le persone sono scelte per essere consultate da un generatore di numeri casuali, applicabile alla regione in studio.
Se si desidera applicare un questionario ai dipendenti di una grande azienda, la selezione degli intervistati può essere utilizzata tramite il numero del dipendente o il numero di carta di identità.
Questo numero deve anche essere scelto in modo casuale, utilizzando un generatore di numeri casuali, ad esempio.
Figura 3. Un questionario può essere applicato selezionando casualmente i partecipanti. Fonte: Pixabay. QA
Nel caso in cui lo studio sia sulle parti prodotte da una macchina, le parti devono essere scelte in modo casuale, ma di lotti realizzati in momenti diversi della giornata o in giorni o settimane diversi.
Vantaggi
Semplice campionamento casuale:
- Permette di ridurre i costi di uno studio statistico, poiché non è necessario studiare la popolazione totale per ottenere risultati statisticamente affidabili, con i livelli di fiducia desiderati e il livello di errore richiesto nello studio.
- Evita la distorsione: poiché la scelta degli elementi da studiare è completamente a caso, lo studio riflette fedelmente le caratteristiche della popolazione, sebbene solo una parte dello stesso sia stata studiata.
Svantaggi
- Il metodo non è adeguato nei casi che si desidera conoscere le preferenze in diversi gruppi o strati di popolazione.
In questo caso è preferibile determinare in precedenza i gruppi o i segmenti su cui viene eseguito lo studio. Una volta definiti gli strati o i gruppi, allora se è conveniente per ciascuno di essi applicare un campionamento casuale.
- È molto improbabile che siano ottenute informazioni sui settori delle minoranze, di cui a volte è necessario conoscere le loro caratteristiche.
Può servirti: regola Simpson: formula, dimostrazione, esempi, eserciziAd esempio, se è una campagna su un prodotto costoso, è necessario conoscere le preferenze dei settori delle minoranze più ricchi.
Esercizio risolto
Vogliamo studiare la preferenza della popolazione con il modo in cui la cola di cola, ma non esiste uno studio precedente in quella popolazione, di cui le sue dimensioni sono sconosciute.
D'altra parte, il campione deve essere rappresentativo con un livello di confidenza minimo del 90% e le conclusioni devono avere un errore percentuale del 2%.
-Come determinare la dimensione S del campione?
-Quale sarebbe la dimensione del campione se il margine di errore è costituito fino al 5%?
Soluzione
Poiché la dimensione della popolazione è sconosciuta, per determinare la dimensione del campione, viene utilizzata la formula sopra indicata:
n = (z2P Q)/(E2)
Supponiamo che ci sia la stessa probabilità di preferenza (p) da parte del nostro ristoro di quella non preferenza (q), quindi p = q = 0,5.
D'altra parte, poiché il risultato dello studio deve avere un errore percentuale inferiore al 2%, l'errore relativo sarà 0,02.
Infine, un valore z = 1.645 produce un livello di confidenza al 90%.
In breve, hai i seguenti valori:
Z = 1.645
P = 0,5
Q = 0,5
E = 0,02
Con questi dati viene calcolata la dimensione minima del campione:
N = (1.6452 0,5 0,5)/(0,022) = 1691.3
Ciò significa che lo studio con il margine di errore richiesto e con il livello di fiducia scelto, deve avere un campione di intervistati di almeno 1692 individui, scelti mediante semplice campionamento casuale.
Se si passa da un margine di errore dal 2% al 5%, la nuova dimensione del campione è:
N = (1.6452 0,5 0,5)/(0,052) = 271
Che è un numero significativamente più basso di individui. In conclusione, la dimensione del campione è molto sensibile al margine desiderato nello studio.
Riferimenti
- Berenson, m. 1985.Statistiche per amministrazione ed economia, concetti e applicazioni. Editoriale interamericano.
- Statistiche. Campionamento Casuale. Tratto da: enciclopediaeconomica.com.
- Statistiche. Campionamento. Recuperato da: statistiche.Stuoia.Uson.MX.
- Esplorabile. Campionamento Casuale. Recuperato da: esplorabile.com.
- Moore, d. 2005. Statistiche di base applicate. 2 °. Edizione.
- Netquest. Campionamento Casuale. Recuperato da: netquest.com.
- Wikipedia. Campione statistico. Recuperato da: in.Wikipedia.org